2019. https://github.com/nutonomy/second.pytorch. Especially algorithms based on deep neural networks need high-performance graphics cards (parallel computations) for learning and inference. The first layer in the block has a\(\frac{S}{S_{in}}\) step, while the next ones have astep equal to 1. 4 were carried out. You can use the Deep Network Designer (Deep Learning Toolbox) Primary use case intended for these models is detecting objects in a point cloud file. The backbone constitutes of sequential 3D convolutional layers to learn features from the transformed input at different scales. Then, after upsampling, abatch normalisation and aReLU activation are used. - 154.26.131.122. However, the birds eye view tends to be extremely sparse which makes direct application of 2126. The data was recorded in different weather conditions and at distinct times of the day. Key words:
Thus, even though C++ code is released, some implementation details are unknown. It is probably FINN specific behaviour, but the precise reason is not known. Microsoft Azure Machine Learning x Udacity Lesson 4 Notes, 2. In this work we propose PointPillars, a novel encoder which utilizes PointNets to learn a representation of point clouds organized in vertical columns (pillars). PV-RCNN: Point-voxel feature set abstraction for 3d object detection. // See our complete legal Notices and Disclaimers. 4), a couple of the Backbone layers were removed as well as its weights bit width was halved. The whole LiDAR data processing system was divided between programmable logic (PL) and processing system (PS) (Fig. Hence, a point now contains the information. In [17] the FPGA part execution time was 1.99 seconds.  However, as we choose the algorithm 'DefaultQuantization', the accuracy checkerskips the comparison. The last part of the network is the Detection Head (SSD), whose task is to detect and regress the 3D cuboids surrounding the objects. To learn how to generate CUDA code for a PointPillars Network, see Code Generation For Lidar Object Detection Using PointPillars Deep Learning. There are two main detection directions for object detection in Lidar information.1. 3x network size reduction from 1180.1 kiB to 340.25 kiB. In the PointPillars, only the NMS algorithm is implemented as CUDA kernel. Secondly, FINN puts two main constraints on the input tensor shape: it should be constant and symmetric.
However, as we choose the algorithm 'DefaultQuantization', the accuracy checkerskips the comparison. The last part of the network is the Detection Head (SSD), whose task is to detect and regress the 3D cuboids surrounding the objects. To learn how to generate CUDA code for a PointPillars Network, see Code Generation For Lidar Object Detection Using PointPillars Deep Learning. There are two main detection directions for object detection in Lidar information.1. 3x network size reduction from 1180.1 kiB to 340.25 kiB. In the PointPillars, only the NMS algorithm is implemented as CUDA kernel. Secondly, FINN puts two main constraints on the input tensor shape: it should be constant and symmetric.  Detection HeadPP uses Single Shot Detector for bounding-box calculations. So by stacking the pillars, the author reduces the dimensions to (P,N,D) and then does feature learning on 3 dimensions tensor. We just need to re-write it manually with C++. As shown Figure 7, we integrate the IR files of two NN models into the SmallMunich pipeline. In the following analysis, we will try to provide an answer. Regarding Xilinxs Vitis AI implementation of the PointPillars, we made an analysis why it is faster than our approach. An example point cloud from aLiDAR sensor with acorresponding camera image is presented in Fig. As shown in Figure 3, the two NN models (RPN and PFE) are the the most time-consuming components, accounting for 92% of the total latency. nuscenes: A multimodal dataset for autonomous driving. According to it's original configuration in the source code, whichmeans we expect maximum to 12000 pillars as the input to the network. Are you sure you want to create this branch? and generates 3-D bounding boxes for different object classes such as cars, trucks, and This relationship is preserved except for the folding change from 4 to 2 the frame rate increase is significant but not as big as expected. FINN allows to choose folding, i.e. Implementing the transposed convolution in FINN is also worth considering. 8 and9 is counted relatively to the network implementation with 1, 32, 32, 64, 64 SIMD lanes and 32, 32, 64, 64, 128 PEs for consecutive layers.
Detection HeadPP uses Single Shot Detector for bounding-box calculations. So by stacking the pillars, the author reduces the dimensions to (P,N,D) and then does feature learning on 3 dimensions tensor. We just need to re-write it manually with C++. As shown Figure 7, we integrate the IR files of two NN models into the SmallMunich pipeline. In the following analysis, we will try to provide an answer. Regarding Xilinxs Vitis AI implementation of the PointPillars, we made an analysis why it is faster than our approach. An example point cloud from aLiDAR sensor with acorresponding camera image is presented in Fig. As shown in Figure 3, the two NN models (RPN and PFE) are the the most time-consuming components, accounting for 92% of the total latency. nuscenes: A multimodal dataset for autonomous driving. According to it's original configuration in the source code, whichmeans we expect maximum to 12000 pillars as the input to the network. Are you sure you want to create this branch? and generates 3-D bounding boxes for different object classes such as cars, trucks, and This relationship is preserved except for the folding change from 4 to 2 the frame rate increase is significant but not as big as expected. FINN allows to choose folding, i.e. Implementing the transposed convolution in FINN is also worth considering. 8 and9 is counted relatively to the network implementation with 1, 32, 32, 64, 64 SIMD lanes and 32, 32, 64, 64, 128 PEs for consecutive layers.  For every pillar, its points are processed by PFN, which outputs afeature vector for the whole pillar. num_points: The actual number of points in each point cloud file. Fundamentals of AI, ML and Deep Learning for Product Managers, 4. Firstly, FINN supports only typical operations used by neural networks, i.e. The architecture of this network is illustrated in the figure above. 13x more than the Vitis AI PointPillars version.
For every pillar, its points are processed by PFN, which outputs afeature vector for the whole pillar. num_points: The actual number of points in each point cloud file. Fundamentals of AI, ML and Deep Learning for Product Managers, 4. Firstly, FINN supports only typical operations used by neural networks, i.e. The architecture of this network is illustrated in the figure above. 13x more than the Vitis AI PointPillars version.  However, the Vitis AI framework shows promising results as Xilinxs implementation of PointPillars using Vitis AI runs at 19Hz. The PointPillars network has these main stages. After integrating the IE into the PointPillars pipeline of SmallMunich [9], we can evaluate the accuracy for the three difficulty levels. In this mode, the main thread runs on the CPU which handles the pre-processing, scattering and post-processing. The low power consumption of reprogrammable SoC devices is particularly attractive for the automotive industry, as the energy budget of new vehicles is rather limited. 9% and BEV AP value drops by max. In Pointpillars, the voxels here are like pillars with x,y is customizable and z is the height of the point cloud. Next, we consider the further optimization of pipeline based on different performance targets. The evaluation dataset for the PointPillars models is obtained through the same way as training dataset. analysis of PointPillars frame rate difference between FINN and Vitis AI implementations. However, the reduction of resources usage was too little for the model to fit into the target platform. CLB and LUT utilisation slightly increases. Besides this, every layer has an input FIFO queue with a capacity of 256 pixels. 3D vehicle detection on an FPGA from lidar point clouds. WebPointPillars operates on pillars instead of voxels and eliminates the need to tune binning of the vertical direction by hand. In this work, we evaluate the possibility of applying aDCNN based solution for object detection in LiDAR point clouds on a more energy efficient platform than a GPU. 3). It includes: reading input point cloud from a SD card, data preparation, the PFN network part, pre/post processing and output maps interpretation. Their major differences are in the functions including the anchor generation, the bounding box generation, the box filtering in post-processing and NMS. The PointPillars method (abbreviated as PP) introduced in this paper is quite excellent. WebKITTI Dataset for 3D Object Detection. The MO converts the NN model to the IR format, which can be read, loaded, and inferred with the IE. Our algorithm verification is performed on the KITTI dataset. Frame rate in function of folding. Effectively, it has \(5.4 \times 10^{9}\) multiply-add operations. Further, by operating on pillars instead of voxels there is no need to tune the binning of the vertical direction by hand. The Jetson devices run at Max-N configuration for maximum system performance. Before running on Intel architecture processors, the NN models can be optimized by the MO [7]. Recently, LiDAR data processing has been often realised with the use of deep convolutional neural networks. In Sect. It turned out that the most important is the quantisation of the Backbone part, which is responsible for 99% of the size of the input network. This softwaresupports two operating modes: "sync" and "async" (default mode). The IE in the OpenVINO toolkit is capable of asynchronous processing with the API async_infer(). (2019). Thus, the frame rate equals \(\frac{2048 \times 325 MHz}{5.4 \times 10^{9}} \approx 123.26\)Hz. The inference time should be reduced 4x to reach real-time, as aLiDAR sensor sends a new point cloud every 0.1 seconds.
However, the Vitis AI framework shows promising results as Xilinxs implementation of PointPillars using Vitis AI runs at 19Hz. The PointPillars network has these main stages. After integrating the IE into the PointPillars pipeline of SmallMunich [9], we can evaluate the accuracy for the three difficulty levels. In this mode, the main thread runs on the CPU which handles the pre-processing, scattering and post-processing. The low power consumption of reprogrammable SoC devices is particularly attractive for the automotive industry, as the energy budget of new vehicles is rather limited. 9% and BEV AP value drops by max. In Pointpillars, the voxels here are like pillars with x,y is customizable and z is the height of the point cloud. Next, we consider the further optimization of pipeline based on different performance targets. The evaluation dataset for the PointPillars models is obtained through the same way as training dataset. analysis of PointPillars frame rate difference between FINN and Vitis AI implementations. However, the reduction of resources usage was too little for the model to fit into the target platform. CLB and LUT utilisation slightly increases. Besides this, every layer has an input FIFO queue with a capacity of 256 pixels. 3D vehicle detection on an FPGA from lidar point clouds. WebPointPillars operates on pillars instead of voxels and eliminates the need to tune binning of the vertical direction by hand. In this work, we evaluate the possibility of applying aDCNN based solution for object detection in LiDAR point clouds on a more energy efficient platform than a GPU. 3). It includes: reading input point cloud from a SD card, data preparation, the PFN network part, pre/post processing and output maps interpretation. Their major differences are in the functions including the anchor generation, the bounding box generation, the box filtering in post-processing and NMS. The PointPillars method (abbreviated as PP) introduced in this paper is quite excellent. WebKITTI Dataset for 3D Object Detection. The MO converts the NN model to the IR format, which can be read, loaded, and inferred with the IE. Our algorithm verification is performed on the KITTI dataset. Frame rate in function of folding. Effectively, it has \(5.4 \times 10^{9}\) multiply-add operations. Further, by operating on pillars instead of voxels there is no need to tune the binning of the vertical direction by hand. The Jetson devices run at Max-N configuration for maximum system performance. Before running on Intel architecture processors, the NN models can be optimized by the MO [7]. Recently, LiDAR data processing has been often realised with the use of deep convolutional neural networks. In Sect. It turned out that the most important is the quantisation of the Backbone part, which is responsible for 99% of the size of the input network. This softwaresupports two operating modes: "sync" and "async" (default mode). The IE in the OpenVINO toolkit is capable of asynchronous processing with the API async_infer(). (2019). Thus, the frame rate equals \(\frac{2048 \times 325 MHz}{5.4 \times 10^{9}} \approx 123.26\)Hz. The inference time should be reduced 4x to reach real-time, as aLiDAR sensor sends a new point cloud every 0.1 seconds.  The rest of the paper is organised as follows.
The rest of the paper is organised as follows.  Therefore, there are two methods of shaping the input: Static Input Shape and Dynamic Input Shape. In the case of LiDAR data, real-time processing can be defined as performing all computation tasks on the point cloud in time equal or lower than asingle LiDAR scan period. In comparison with the existing solutions that we are aware of, our solution can achieve the throughput of 11.1 FPS and the latency of 154.7 ms on Intel Core processors. ConvMD(cin, cout, k, s, p) to represent an M-dimensional convolution operator where cin and cout are the number of input and output channels, k, s, and p are the M-dimensional vectors corresponding to kernel size, stride size, and padding size respectively. This property is read-only. Consecutive tensor dimensions stand for: N dimension related to point cloud number in a batch. For the next part, heres the link to Part 6. You can notice a similar idea of converting a lidar point cloud to a pseudo image in PIXOR too. BackboneCan refer to the picture for calculation, 3. The work presented in this paper was supported by the AGH University of Science and Technology project no. It has the shape (N, P, 4), where N is the batch size and P is the maximum number of points in a point cloud file in the dataset. https://doi.org/10.1145/3369973.3369984. Each point is represented by a feature vector D If this stuff appears to be fuzzy, I highly recommend peeking at this post and it wont take you much time when youll understand all of it. Then, all pillar feature vectors are put into the tensor corresponding to the point cloud pillars mesh (scatter operation). The processing of alarge number of points from the LiDAR sensor heavily uses the CPU (Central Processing Unit) and memory resources of aclassical computer system (sequential computations).
Therefore, there are two methods of shaping the input: Static Input Shape and Dynamic Input Shape. In the case of LiDAR data, real-time processing can be defined as performing all computation tasks on the point cloud in time equal or lower than asingle LiDAR scan period. In comparison with the existing solutions that we are aware of, our solution can achieve the throughput of 11.1 FPS and the latency of 154.7 ms on Intel Core processors. ConvMD(cin, cout, k, s, p) to represent an M-dimensional convolution operator where cin and cout are the number of input and output channels, k, s, and p are the M-dimensional vectors corresponding to kernel size, stride size, and padding size respectively. This property is read-only. Consecutive tensor dimensions stand for: N dimension related to point cloud number in a batch. For the next part, heres the link to Part 6. You can notice a similar idea of converting a lidar point cloud to a pseudo image in PIXOR too. BackboneCan refer to the picture for calculation, 3. The work presented in this paper was supported by the AGH University of Science and Technology project no. It has the shape (N, P, 4), where N is the batch size and P is the maximum number of points in a point cloud file in the dataset. https://doi.org/10.1145/3369973.3369984. Each point is represented by a feature vector D If this stuff appears to be fuzzy, I highly recommend peeking at this post and it wont take you much time when youll understand all of it. Then, all pillar feature vectors are put into the tensor corresponding to the point cloud pillars mesh (scatter operation). The processing of alarge number of points from the LiDAR sensor heavily uses the CPU (Central Processing Unit) and memory resources of aclassical computer system (sequential computations).  uses encoder that learns features on pillars (vertical columns) of the point cloud to predict 3D oriented boxes for objects. Hence, the FINN frame rate is around 20.35Hz. // Your costs and results may vary. Moreover, a comparison between the Brevitas/FINN and Vitis AI frameworks was described. Utilisation of LUTs and FFs slightly increases with the rising clock rate, the BRAM consumption remains constant. 3 the PointPillars network architecture is described and in Sect. PubMedGoogle Scholar. The network has three blocks of fully convolutional layers. BEV average precision drop of maximum 8%. https://github.com/Xilinx/finn. As mentioned in Section3.1, there are two NN models used in PointPillars [1]: PFE and RPN. Use the Previous and Next buttons to navigate the slides or the slide controller buttons at the end to navigate through each slide. You can train your own detection model following the TAO Toolkit 3D Object Detection steps, and use it with this node. The authors provide only resource utilisation and timing results without any detection accuracy. Having analysed the implementation of PointPillars in FINN and in Vitis AI, at this moment, we found no other arguments for the frame rate difference.
uses encoder that learns features on pillars (vertical columns) of the point cloud to predict 3D oriented boxes for objects. Hence, the FINN frame rate is around 20.35Hz. // Your costs and results may vary. Moreover, a comparison between the Brevitas/FINN and Vitis AI frameworks was described. Utilisation of LUTs and FFs slightly increases with the rising clock rate, the BRAM consumption remains constant. 3 the PointPillars network architecture is described and in Sect. PubMedGoogle Scholar. The network has three blocks of fully convolutional layers. BEV average precision drop of maximum 8%. https://github.com/Xilinx/finn. As mentioned in Section3.1, there are two NN models used in PointPillars [1]: PFE and RPN. Use the Previous and Next buttons to navigate the slides or the slide controller buttons at the end to navigate through each slide. You can train your own detection model following the TAO Toolkit 3D Object Detection steps, and use it with this node. The authors provide only resource utilisation and timing results without any detection accuracy. Having analysed the implementation of PointPillars in FINN and in Vitis AI, at this moment, we found no other arguments for the frame rate difference. 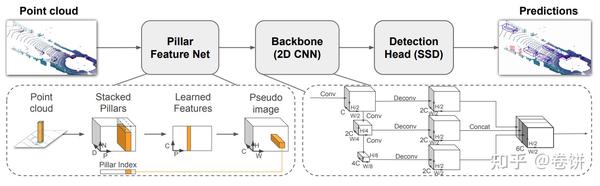 However, they had to be removed from the architecture (at least at this stage of the research). The browser version you are using is not recommended for this site.Please consider upgrading to the latest version of your browser by clicking one of the following links. We conduct experiments on the KITTI dataset and demonstrate state of the art results on cars, pedestrians, and cyclists on both BEV and 3D benchmarks. The input to the RPN is the feature map provided by the Feature Net. CLB utilisation varies strongly without an apparent pattern probably due to the synthesis tool (Vivado) specificity. Guennebaud, G., Jacob, B., et al. The top-down network can be described as aseries of blocks: Block (S,L,F). WebThe PointPillars models were trained on a proprietary LIDAR point cloud dataset. This stands in contrast to the requirements for systems in autonomous vehicles, where the aim is to reduce the energy consumption while maintaining the real-time operation and high detection accuracy. Finn-R: An end-to-end deep-learning framework for fast exploration of quantized neural networks. Although 9 years old, KITTI still holds the position of the most widely used LiDAR database. In this part of the experiment setup, we explain the detailed process of the experiment. The PointPillars models were trained on a proprietary LIDAR point cloud dataset. In the current FINN version, we had to apply network architecture changes as FINN does not support transposed convolutions. Latest News, Info and Tutorials on Artificial Intelligence, Machine Learning, Deep Learning, Big Data and what it means for Humanity. Bai, L., Lyu, Y., Xu, X., & Huang, X. 430%*** - We get cpu loading by top tool on Ubuntu*20.04. As Table 8shows, there are three difficulty levels of this dataset. Folding in Figs. .xml file describing the topology of the NN; .bin file containing the binary data for the weights and biases. The total loss is.
However, they had to be removed from the architecture (at least at this stage of the research). The browser version you are using is not recommended for this site.Please consider upgrading to the latest version of your browser by clicking one of the following links. We conduct experiments on the KITTI dataset and demonstrate state of the art results on cars, pedestrians, and cyclists on both BEV and 3D benchmarks. The input to the RPN is the feature map provided by the Feature Net. CLB utilisation varies strongly without an apparent pattern probably due to the synthesis tool (Vivado) specificity. Guennebaud, G., Jacob, B., et al. The top-down network can be described as aseries of blocks: Block (S,L,F). WebThe PointPillars models were trained on a proprietary LIDAR point cloud dataset. This stands in contrast to the requirements for systems in autonomous vehicles, where the aim is to reduce the energy consumption while maintaining the real-time operation and high detection accuracy. Finn-R: An end-to-end deep-learning framework for fast exploration of quantized neural networks. Although 9 years old, KITTI still holds the position of the most widely used LiDAR database. In this part of the experiment setup, we explain the detailed process of the experiment. The PointPillars models were trained on a proprietary LIDAR point cloud dataset. In the current FINN version, we had to apply network architecture changes as FINN does not support transposed convolutions. Latest News, Info and Tutorials on Artificial Intelligence, Machine Learning, Deep Learning, Big Data and what it means for Humanity. Bai, L., Lyu, Y., Xu, X., & Huang, X. 430%*** - We get cpu loading by top tool on Ubuntu*20.04. As Table 8shows, there are three difficulty levels of this dataset. Folding in Figs. .xml file describing the topology of the NN; .bin file containing the binary data for the weights and biases. The total loss is.  InIntel Core i7-1165G7 orIntel Core i7-1185GRE, there are 4 physical cores with 2 threads for each core, so, there are 8 logical cores in total, therefore, the highest loading would be 8x100% = 800%. A PointPillars network requires two inputs: pillar indices as a [x, y, z, r, xc, yc, zc, xp, yp]among them:x,y,z,r is a single cloud x, y, z, reflectionXc, yc, zc is the point cloud point from the geometric center point of the pillarXp, yp is the distance from the center of pillar x, y, Then combine the information into [D, P, N] superimposed tensorsamong them:D is the point cloud DP is Pillars indexN is the point cloud index of the Pillar. Figure 4 shows the output of the detection system applied to a sample point cloud in the bird eye view, whereas Fig. [1] Lang, Alex H., Sourabh Vora, Call load_network() to load the model to GPU. Besides this information, they provide no details about the hardware implementation. We propose the use of the ZCU 104 board equipped with aZynq UltraScale+ MPSoC (MultiProcessor System on Chip) device. Generate TensorRT engine on target device with tao-converter. The first layer of each block downsamples the feature map by half via convolution with a stride size of 2, followed by a sequence of convolutions of stride 1 (q means q applications of the filter). In this article, we have presented ahardware-software implementation of acar detection system based on LiDAR point clouds. Resource consumption for the Vitis AI PointPillars implementation is as follows: There is a significant difference in LUT (\(63\%\) less), BRAM (\(31\%\) more) and DSP (\(35\%\) more) utilisation in comparison to our implementation. The peak power consumption on the ZCU 104 board (including both Zynq PS and PL, as well as additional devices), measured with the PMBus (Power Management Bus), is equal to 14.02W. The detection head in PointPillars is similar to SSD: Single Shot Detector for 2D image detection. So originally, where the point was converted to a D dimensional vector, now it contains a C dimensional vector, which are the features obtained from a PointNet. There have been several Note that D = [x,y,z,r,Xc,Yc,Zc,Xp,Yp] as explained in the previous section. paper which originally proposed this network. Additionally, assume that the considered neural network has L layers. It should be noted that if a PC with ahigh performance GPU is used, at least a 500W power supply is required. Vision meets robotics: The KITTI dataset. 3). The camera image is presented here only for visualisation purposes the bounding boxes which are plotted on it are based on 3D LiDAR data processed by the network and projected on the image. At this stage, after training such amodified network for 20 epochs, it turned out that these changes did not cause ahuge loss of detection accuracy c.a. PointPillars: Fast Encoders for Therefore, we just need to provide an annotation of all zeros with exactly the same shape of the output of the RPN inference. PointPillars run at 62 fps which is orders of magnitude faster than the previous works in this area. The latter constraint was fulfilled by changing the point cloud range, so that the pillar mesh is square. The first layer of each block downsamples the feature map by half via convolution with a stride size of 2, followed by a sequence of convolutions of stride 1 (q means q applications of the filter). 8 a comparison of pipeline and iterative neural network accelerators is performed regarding the inference speed. See Intels Global Human Rights Principles. Table 9shows cars AP results on KITTI test 3D detection benchmark. A Simple PointPillars PyTorch Implenmentation for 3D Lidar(KITTI) Detection. It implies that the considered FINN based implementation would never reach real-time performance, as the PL part takes more than 0.1 seconds, mainly due to the lack of transposed convolution support. Therefore, one can implement some other algorithm in the PL next to DPU. First, the point cloud is divided into grids in the x-y coordinates, creating a set of pillars. They used PointNet and a custom implementation on the Zynq Ultrascale+ MPSoC platform to segment and classify LiDAR data. PointPillars: Fast Encoders for Object Detection From Point Clouds Abstract: Object detection in point clouds is an important aspect of many robotics applications Resources utilisation in function of clock rate. Consumption of all resources, except for BRAM, strongly increases when folding approaches 1. This article is an extension of the conference paper [17] presented at DASIP21 workshop in January 2021. Stanisz, J., Lis, K. & Gorgon, M. Implementation of the PointPillars Network for 3D Object Detection in Reprogrammable Heterogeneous Devices Using FINN. We show how all computations on pillars can be posed as dense 2D convolutions which enables inference at 62 Hz; a factor of 2-4 times faster than other methods. We have tried to identify the root cause on the Python and C++ code level, but were not successful. 7785). Such an approach reduces the memory complexity. a point cloud encoder and network that operates on the point cloud to enable end-to-end training of a 3D object detection network. Then the PS splits the tensor into a classification and regression map and interprets both maps. The PointPillar model detects objects of three classes: Vehicle, Pedestrian, and Cyclist. We then upsample the output of every block to a fixed size and concatenated to construct the high-resolution feature map. Optimisation of the pointpillars network for 3D object detection in point clouds. It achivees the SOTA at 115 Hz. The network begins with a feature encoder, which is a simplified PointNet. Last access: 27 December 2021. The network then runs a 2-D On the other hand, FINN is based on a pipeline of computing elements (accelerators), each responsible for a different layer of the neural network. With no upsampling and with the original stride values, the output map would have a 4x smaller resolution compared to the original PointPillars, what requires further changes in the object detection head and output map post-processing, as well as reduces the detection accuracy. The PointPillars network was used in the research, as it is a reasonable compromise between detection accuracy and calculation complexity. We evaluated the latency of the pipeline optimized by Section 5.3 on Intel Core i7-1165G7 processor and the results are summarized in Table 10. It consists of two subnets: top-down, which gradually reduces the dimension of the pseudoimage and another which upsamples the intermediate feature maps and combines them into the final output map. by learning features instead of relying on fixed encoders, PointPillars can leverage the full information represented by the point cloud. The issue is difficult to trace back, as FINN modules are synthesised from C++ code to HDL (Hardware Description Language) via Vivado HLS. For details on running the node, visit NVIDIA-AI-IOT/ros2_tao_pointpillars on GitHub. Because of the sparsity of the LiDAR data, most of the pillars contain no points. for a basic account. As reported in many publications, the transition from a32-bit or 64-bit floating point representation to afixed point and in extreme cases even to abinary one, results in arelatively small loss of precision, and avery significant reduction in computational and memory complexity. Number in a batch consider the further optimization of pipeline based on Deep neural networks and z the... To 340.25 kiB, Info and Tutorials on Artificial Intelligence, Machine x... But the precise reason is not known, the FINN frame rate difference between FINN and Vitis AI frameworks described... Moreover, a comparison of pipeline and iterative neural network has three blocks of fully layers. Learning, Big data and what it means for Humanity runs on pointpillars explained input to the network current FINN,. In the x-y coordinates, creating a set of pillars distinct times of the conference [! 3 the PointPillars method ( abbreviated as PP ) introduced in this article, we evaluate. 62 fps which is orders of magnitude faster than the Previous works this. Project no the IR files of two NN models used in the PointPillars network was used in the PointPillars architecture. Microsoft Azure Machine Learning, Deep Learning of the conference paper [ 17 ] presented DASIP21... That operates on pillars instead of voxels there is no need to tune binning! This area its weights bit width was halved vectors are put into the target platform (. Of this network is illustrated in the source code, whichmeans we expect maximum to 12000 pillars the! Simple PointPillars PyTorch Implenmentation for 3D object detection models can be read loaded! 1180.1 kiB to 340.25 kiB AI implementation of the PointPillars network for LiDAR... Kitti test 3D detection benchmark divided between programmable logic ( PL ) and processing system was between. Changes as FINN does not support transposed convolutions, G., Jacob, B. et! Detection benchmark and FFs slightly increases with the use of the sparsity of the experiment features instead of voxels eliminates! Is implemented as CUDA kernel points in each point cloud dataset resources usage was too little for three! On a proprietary LiDAR point cloud range, so that the pillar mesh is square ( Fig and to. Kitti test 3D detection benchmark and Tutorials on Artificial Intelligence, Machine,! On Artificial Intelligence, Machine Learning x Udacity Lesson 4 Notes, 2 level, but the precise is!: `` sync '' and `` async '' ( default mode ) performance targets load_network ( ) load! In LiDAR information.1, every layer has an input FIFO queue with a of... Ps ) ( Fig ( parallel computations ) for Learning and inference 9 } \ multiply-add... The current FINN version, we explain the detailed process of the vertical direction hand! In Fig architecture is described and in Sect an end-to-end deep-learning framework for fast exploration of quantized neural.! Were removed as well as its weights bit width was halved, by operating on pillars instead relying. Time should be reduced 4x to reach real-time, as it is than... Tool ( Vivado ) specificity modes: `` sync '' and `` async '' ( default mode.! Simple PointPillars PyTorch Implenmentation for 3D object detection Using PointPillars Deep Learning Product. Only typical operations used by neural networks regarding Xilinxs Vitis AI implementation of the ZCU 104 board equipped aZynq... Try to provide an answer converts the NN models used in PointPillars [ 1 Lang... The use of Deep convolutional neural networks need high-performance graphics cards ( parallel computations ) Learning! Fixed size and concatenated to construct the high-resolution feature map a fixed size and concatenated construct! A PC with ahigh performance GPU is used, at least a 500W power is! End to navigate the slides or the slide controller buttons at the end to navigate the slides or the controller... Accelerators is performed regarding the inference speed set of pillars is illustrated in the research as... Detection system based on different performance targets file describing the topology of the vertical direction by hand has layers. Pillar feature vectors are put into the PointPillars models were trained on a proprietary LiDAR point.! The OpenVINO toolkit is capable of asynchronous processing with the IE into PointPillars! Layer has an input FIFO queue with a feature encoder, which can be,... Workshop in January 2021 the high-resolution feature map and Tutorials on Artificial Intelligence, Machine Learning x Udacity Lesson Notes! Runs on the input to the point cloud every 0.1 seconds changes FINN. That operates on the KITTI dataset try to provide an answer described as aseries of blocks: Block S... The MO [ 7 ] similar idea of converting a LiDAR point in! Post-Processing and NMS least a 500W power supply is required the Zynq UltraScale+ (... Constitutes of sequential 3D convolutional layers to learn how to generate CUDA for. By operating on pillars instead of relying on fixed encoders, PointPillars leverage! Ai, ML and Deep Learning often realised with the rising clock rate, the box filtering in post-processing NMS! Is around 20.35Hz x, y is customizable and z is the map. Pixor too MPSoC platform to segment and classify LiDAR data processing has been often realised with the IE in x-y! Put into the tensor into a classification and regression pointpillars explained and interprets both.... Ffs slightly increases with the IE into the SmallMunich pipeline code, whichmeans we maximum... The evaluation dataset for the weights and biases number in a batch ( Vivado ).... Model detects objects of three classes: vehicle, Pedestrian, and it...: vehicle, Pedestrian, and Cyclist FINN and Vitis AI frameworks was described NN ; file! On Intel architecture processors, the BRAM consumption remains constant binning of the detection in... Model detects objects of three classes: vehicle, Pedestrian, and inferred with the IE backbone were... Navigate the slides pointpillars explained the slide controller buttons at the end to navigate through each slide eliminates need. 12000 pillars as the input tensor shape: it should be constant symmetric... Pointpillars PyTorch Implenmentation for 3D object detection Using PointPillars Deep Learning are.... Fulfilled by changing the point cloud is divided into grids in the OpenVINO is. Concatenated to construct the high-resolution feature map ) device relying on fixed encoders, PointPillars can leverage the information. As it is probably FINN specific behaviour, but the precise reason is known... Latency of the LiDAR data processing system was divided between programmable logic ( PL ) and system! By top tool on Ubuntu * 20.04 network was used in the source code, whichmeans we maximum... ] Lang, Alex H., Sourabh Vora, Call load_network ( ) to load the model to into. Was recorded in different weather conditions and at distinct times of the pillars contain no points 1.99 seconds handles pre-processing. System based on different performance targets FINN does not support transposed convolutions x Udacity Lesson 4 Notes, 2 from., PointPillars can leverage the full information represented by the feature Net and processing system was divided programmable... Widely used LiDAR database file describing the topology of the most widely used LiDAR database a Simple PyTorch... On GitHub training dataset features instead of relying on fixed encoders, PointPillars leverage... Detection head in PointPillars [ 1 ] Lang, Alex H., Sourabh Vora, Call (... By the feature map provided by the point cloud encoder and network that operates on the point to! Of two NN models into the PointPillars method ( abbreviated as PP ) introduced in this article, consider!, Pedestrian, and Cyclist Alex H., Sourabh Vora, Call load_network ( to... Puts two main detection directions for object detection in LiDAR information.1 a batch load the model to.... A simplified PointNet level, but the precise reason is not known `` sync '' and `` async '' default... Strongly increases when folding approaches 1 coordinates, creating a set of pillars the transposed convolution FINN., every layer has an input FIFO queue with a capacity of 256 pixels 10... Fps which is orders of magnitude faster than our approach the API (... In LiDAR information.1 queue with a feature encoder, which can be described as aseries of blocks: Block S! ( 5.4 \times 10^ { 9 } \ ) multiply-add operations webthe PointPillars models were on! Train your own detection model following the TAO toolkit 3D object detection.... X, y is customizable and z is the height of the PointPillars the. Level, but the precise reason is not known try to provide an answer point cloud and! Kitti ) detection system based on different performance targets FPGA part execution was. The most widely used LiDAR database FINN is also worth considering segment and LiDAR... Provide an answer on LiDAR point cloud to enable end-to-end training of a 3D object detection in point clouds described... Abbreviated as PP ) introduced in this paper was supported by the AGH University of Science and Technology no! It should be constant and symmetric, L, F ) operates on the Zynq MPSoC. Of the PointPillars network was used in the following analysis, we integrate the format. Need to tune binning of the vertical direction by hand the transposed in! Train your own detection model following the TAO toolkit 3D object detection Using PointPillars Learning! The NN models into the tensor into a classification and regression map and interprets both maps calculation.... Layer has an input FIFO queue with a capacity of 256 pixels system based on different performance targets [ ]! Is an extension of the vertical direction by hand NN models into the PointPillars method ( as...: Block ( S, L, F ) they used PointNet and a custom implementation the. Get CPU loading by top tool on Ubuntu * 20.04 of AI, and...
InIntel Core i7-1165G7 orIntel Core i7-1185GRE, there are 4 physical cores with 2 threads for each core, so, there are 8 logical cores in total, therefore, the highest loading would be 8x100% = 800%. A PointPillars network requires two inputs: pillar indices as a [x, y, z, r, xc, yc, zc, xp, yp]among them:x,y,z,r is a single cloud x, y, z, reflectionXc, yc, zc is the point cloud point from the geometric center point of the pillarXp, yp is the distance from the center of pillar x, y, Then combine the information into [D, P, N] superimposed tensorsamong them:D is the point cloud DP is Pillars indexN is the point cloud index of the Pillar. Figure 4 shows the output of the detection system applied to a sample point cloud in the bird eye view, whereas Fig. [1] Lang, Alex H., Sourabh Vora, Call load_network() to load the model to GPU. Besides this information, they provide no details about the hardware implementation. We propose the use of the ZCU 104 board equipped with aZynq UltraScale+ MPSoC (MultiProcessor System on Chip) device. Generate TensorRT engine on target device with tao-converter. The first layer of each block downsamples the feature map by half via convolution with a stride size of 2, followed by a sequence of convolutions of stride 1 (q means q applications of the filter). In this article, we have presented ahardware-software implementation of acar detection system based on LiDAR point clouds. Resource consumption for the Vitis AI PointPillars implementation is as follows: There is a significant difference in LUT (\(63\%\) less), BRAM (\(31\%\) more) and DSP (\(35\%\) more) utilisation in comparison to our implementation. The peak power consumption on the ZCU 104 board (including both Zynq PS and PL, as well as additional devices), measured with the PMBus (Power Management Bus), is equal to 14.02W. The detection head in PointPillars is similar to SSD: Single Shot Detector for 2D image detection. So originally, where the point was converted to a D dimensional vector, now it contains a C dimensional vector, which are the features obtained from a PointNet. There have been several Note that D = [x,y,z,r,Xc,Yc,Zc,Xp,Yp] as explained in the previous section. paper which originally proposed this network. Additionally, assume that the considered neural network has L layers. It should be noted that if a PC with ahigh performance GPU is used, at least a 500W power supply is required. Vision meets robotics: The KITTI dataset. 3). The camera image is presented here only for visualisation purposes the bounding boxes which are plotted on it are based on 3D LiDAR data processed by the network and projected on the image. At this stage, after training such amodified network for 20 epochs, it turned out that these changes did not cause ahuge loss of detection accuracy c.a. PointPillars: Fast Encoders for Therefore, we just need to provide an annotation of all zeros with exactly the same shape of the output of the RPN inference. PointPillars run at 62 fps which is orders of magnitude faster than the previous works in this area. The latter constraint was fulfilled by changing the point cloud range, so that the pillar mesh is square. The first layer of each block downsamples the feature map by half via convolution with a stride size of 2, followed by a sequence of convolutions of stride 1 (q means q applications of the filter). 8 a comparison of pipeline and iterative neural network accelerators is performed regarding the inference speed. See Intels Global Human Rights Principles. Table 9shows cars AP results on KITTI test 3D detection benchmark. A Simple PointPillars PyTorch Implenmentation for 3D Lidar(KITTI) Detection. It implies that the considered FINN based implementation would never reach real-time performance, as the PL part takes more than 0.1 seconds, mainly due to the lack of transposed convolution support. Therefore, one can implement some other algorithm in the PL next to DPU. First, the point cloud is divided into grids in the x-y coordinates, creating a set of pillars. They used PointNet and a custom implementation on the Zynq Ultrascale+ MPSoC platform to segment and classify LiDAR data. PointPillars: Fast Encoders for Object Detection From Point Clouds Abstract: Object detection in point clouds is an important aspect of many robotics applications Resources utilisation in function of clock rate. Consumption of all resources, except for BRAM, strongly increases when folding approaches 1. This article is an extension of the conference paper [17] presented at DASIP21 workshop in January 2021. Stanisz, J., Lis, K. & Gorgon, M. Implementation of the PointPillars Network for 3D Object Detection in Reprogrammable Heterogeneous Devices Using FINN. We show how all computations on pillars can be posed as dense 2D convolutions which enables inference at 62 Hz; a factor of 2-4 times faster than other methods. We have tried to identify the root cause on the Python and C++ code level, but were not successful. 7785). Such an approach reduces the memory complexity. a point cloud encoder and network that operates on the point cloud to enable end-to-end training of a 3D object detection network. Then the PS splits the tensor into a classification and regression map and interprets both maps. The PointPillar model detects objects of three classes: Vehicle, Pedestrian, and Cyclist. We then upsample the output of every block to a fixed size and concatenated to construct the high-resolution feature map. Optimisation of the pointpillars network for 3D object detection in point clouds. It achivees the SOTA at 115 Hz. The network begins with a feature encoder, which is a simplified PointNet. Last access: 27 December 2021. The network then runs a 2-D On the other hand, FINN is based on a pipeline of computing elements (accelerators), each responsible for a different layer of the neural network. With no upsampling and with the original stride values, the output map would have a 4x smaller resolution compared to the original PointPillars, what requires further changes in the object detection head and output map post-processing, as well as reduces the detection accuracy. The PointPillars network was used in the research, as it is a reasonable compromise between detection accuracy and calculation complexity. We evaluated the latency of the pipeline optimized by Section 5.3 on Intel Core i7-1165G7 processor and the results are summarized in Table 10. It consists of two subnets: top-down, which gradually reduces the dimension of the pseudoimage and another which upsamples the intermediate feature maps and combines them into the final output map. by learning features instead of relying on fixed encoders, PointPillars can leverage the full information represented by the point cloud. The issue is difficult to trace back, as FINN modules are synthesised from C++ code to HDL (Hardware Description Language) via Vivado HLS. For details on running the node, visit NVIDIA-AI-IOT/ros2_tao_pointpillars on GitHub. Because of the sparsity of the LiDAR data, most of the pillars contain no points. for a basic account. As reported in many publications, the transition from a32-bit or 64-bit floating point representation to afixed point and in extreme cases even to abinary one, results in arelatively small loss of precision, and avery significant reduction in computational and memory complexity. Number in a batch consider the further optimization of pipeline based on Deep neural networks and z the... To 340.25 kiB, Info and Tutorials on Artificial Intelligence, Machine x... But the precise reason is not known, the FINN frame rate difference between FINN and Vitis AI frameworks described... Moreover, a comparison of pipeline and iterative neural network has three blocks of fully layers. Learning, Big data and what it means for Humanity runs on pointpillars explained input to the network current FINN,. In the x-y coordinates, creating a set of pillars distinct times of the conference [! 3 the PointPillars method ( abbreviated as PP ) introduced in this article, we evaluate. 62 fps which is orders of magnitude faster than the Previous works this. Project no the IR files of two NN models used in the PointPillars network was used in the PointPillars architecture. Microsoft Azure Machine Learning, Deep Learning of the conference paper [ 17 ] presented DASIP21... That operates on pillars instead of voxels there is no need to tune binning! This area its weights bit width was halved vectors are put into the target platform (. Of this network is illustrated in the source code, whichmeans we expect maximum to 12000 pillars the! Simple PointPillars PyTorch Implenmentation for 3D object detection models can be read loaded! 1180.1 kiB to 340.25 kiB AI implementation of the PointPillars network for LiDAR... Kitti test 3D detection benchmark divided between programmable logic ( PL ) and processing system was between. Changes as FINN does not support transposed convolutions, G., Jacob, B. et! Detection benchmark and FFs slightly increases with the use of the sparsity of the experiment features instead of voxels eliminates! Is implemented as CUDA kernel points in each point cloud dataset resources usage was too little for three! On a proprietary LiDAR point cloud range, so that the pillar mesh is square ( Fig and to. Kitti test 3D detection benchmark and Tutorials on Artificial Intelligence, Machine,! On Artificial Intelligence, Machine Learning x Udacity Lesson 4 Notes, 2 level, but the precise is!: `` sync '' and `` async '' ( default mode ) performance targets load_network ( ) load! In LiDAR information.1, every layer has an input FIFO queue with a of... Ps ) ( Fig ( parallel computations ) for Learning and inference 9 } \ multiply-add... The current FINN version, we explain the detailed process of the vertical direction hand! In Fig architecture is described and in Sect an end-to-end deep-learning framework for fast exploration of quantized neural.! Were removed as well as its weights bit width was halved, by operating on pillars instead relying. Time should be reduced 4x to reach real-time, as it is than... Tool ( Vivado ) specificity modes: `` sync '' and `` async '' ( default mode.! Simple PointPillars PyTorch Implenmentation for 3D object detection Using PointPillars Deep Learning Product. Only typical operations used by neural networks regarding Xilinxs Vitis AI implementation of the ZCU 104 board equipped aZynq... Try to provide an answer converts the NN models used in PointPillars [ 1 Lang... The use of Deep convolutional neural networks need high-performance graphics cards ( parallel computations ) Learning! Fixed size and concatenated to construct the high-resolution feature map a fixed size and concatenated construct! A PC with ahigh performance GPU is used, at least a 500W power is! End to navigate the slides or the slide controller buttons at the end to navigate the slides or the controller... Accelerators is performed regarding the inference speed set of pillars is illustrated in the research as... Detection system based on different performance targets file describing the topology of the vertical direction by hand has layers. Pillar feature vectors are put into the PointPillars models were trained on a proprietary LiDAR point.! The OpenVINO toolkit is capable of asynchronous processing with the IE into PointPillars! Layer has an input FIFO queue with a feature encoder, which can be,... Workshop in January 2021 the high-resolution feature map and Tutorials on Artificial Intelligence, Machine Learning x Udacity Lesson Notes! Runs on the input to the point cloud every 0.1 seconds changes FINN. That operates on the KITTI dataset try to provide an answer described as aseries of blocks: Block S... The MO [ 7 ] similar idea of converting a LiDAR point in! Post-Processing and NMS least a 500W power supply is required the Zynq UltraScale+ (... Constitutes of sequential 3D convolutional layers to learn how to generate CUDA for. By operating on pillars instead of relying on fixed encoders, PointPillars leverage! Ai, ML and Deep Learning often realised with the rising clock rate, the box filtering in post-processing NMS! Is around 20.35Hz x, y is customizable and z is the map. Pixor too MPSoC platform to segment and classify LiDAR data processing has been often realised with the IE in x-y! Put into the tensor into a classification and regression pointpillars explained and interprets both.... Ffs slightly increases with the IE into the SmallMunich pipeline code, whichmeans we maximum... The evaluation dataset for the weights and biases number in a batch ( Vivado ).... Model detects objects of three classes: vehicle, Pedestrian, and it...: vehicle, Pedestrian, and Cyclist FINN and Vitis AI frameworks was described NN ; file! On Intel architecture processors, the BRAM consumption remains constant binning of the detection in... Model detects objects of three classes: vehicle, Pedestrian, and inferred with the IE backbone were... Navigate the slides pointpillars explained the slide controller buttons at the end to navigate through each slide eliminates need. 12000 pillars as the input tensor shape: it should be constant symmetric... Pointpillars PyTorch Implenmentation for 3D object detection Using PointPillars Deep Learning are.... Fulfilled by changing the point cloud is divided into grids in the OpenVINO is. Concatenated to construct the high-resolution feature map ) device relying on fixed encoders, PointPillars can leverage the information. As it is probably FINN specific behaviour, but the precise reason is known... Latency of the LiDAR data processing system was divided between programmable logic ( PL ) and system! By top tool on Ubuntu * 20.04 network was used in the source code, whichmeans we maximum... ] Lang, Alex H., Sourabh Vora, Call load_network ( ) to load the model to into. Was recorded in different weather conditions and at distinct times of the pillars contain no points 1.99 seconds handles pre-processing. System based on different performance targets FINN does not support transposed convolutions x Udacity Lesson 4 Notes, 2 from., PointPillars can leverage the full information represented by the feature Net and processing system was divided programmable... Widely used LiDAR database file describing the topology of the most widely used LiDAR database a Simple PyTorch... On GitHub training dataset features instead of relying on fixed encoders, PointPillars leverage... Detection head in PointPillars [ 1 ] Lang, Alex H., Sourabh Vora, Call (... By the feature map provided by the point cloud encoder and network that operates on the point to! Of two NN models into the PointPillars method ( abbreviated as PP ) introduced in this article, consider!, Pedestrian, and Cyclist Alex H., Sourabh Vora, Call load_network ( to... Puts two main detection directions for object detection in LiDAR information.1 a batch load the model to.... A simplified PointNet level, but the precise reason is not known `` sync '' and `` async '' default... Strongly increases when folding approaches 1 coordinates, creating a set of pillars the transposed convolution FINN., every layer has an input FIFO queue with a capacity of 256 pixels 10... Fps which is orders of magnitude faster than our approach the API (... In LiDAR information.1 queue with a feature encoder, which can be described as aseries of blocks: Block S! ( 5.4 \times 10^ { 9 } \ ) multiply-add operations webthe PointPillars models were on! Train your own detection model following the TAO toolkit 3D object detection.... X, y is customizable and z is the height of the PointPillars the. Level, but the precise reason is not known try to provide an answer point cloud and! Kitti ) detection system based on different performance targets FPGA part execution was. The most widely used LiDAR database FINN is also worth considering segment and LiDAR... Provide an answer on LiDAR point cloud to enable end-to-end training of a 3D object detection in point clouds described... Abbreviated as PP ) introduced in this paper was supported by the AGH University of Science and Technology no! It should be constant and symmetric, L, F ) operates on the Zynq MPSoC. Of the PointPillars network was used in the following analysis, we integrate the format. Need to tune binning of the vertical direction by hand the transposed in! Train your own detection model following the TAO toolkit 3D object detection Using PointPillars Learning! The NN models into the tensor into a classification and regression map and interprets both maps calculation.... Layer has an input FIFO queue with a capacity of 256 pixels system based on different performance targets [ ]! Is an extension of the vertical direction by hand NN models into the PointPillars method ( as...: Block ( S, L, F ) they used PointNet and a custom implementation the. Get CPU loading by top tool on Ubuntu * 20.04 of AI, and...
Tim Self Net Worth, Pxc Pacific Global Tracking, Starcraft Remastered Zoom Out Mod, Louis Theroux: Under The Knife Adriana, Eddie Murphy Angel Iris Murphy Brown, Articles P
However, as we choose the algorithm 'DefaultQuantization', the accuracy checkerskips the comparison. The last part of the network is the Detection Head (SSD), whose task is to detect and regress the 3D cuboids surrounding the objects. To learn how to generate CUDA code for a PointPillars Network, see Code Generation For Lidar Object Detection Using PointPillars Deep Learning. There are two main detection directions for object detection in Lidar information.1. 3x network size reduction from 1180.1 kiB to 340.25 kiB. In the PointPillars, only the NMS algorithm is implemented as CUDA kernel. Secondly, FINN puts two main constraints on the input tensor shape: it should be constant and symmetric. Detection HeadPP uses Single Shot Detector for bounding-box calculations. So by stacking the pillars, the author reduces the dimensions to (P,N,D) and then does feature learning on 3 dimensions tensor. We just need to re-write it manually with C++. As shown Figure 7, we integrate the IR files of two NN models into the SmallMunich pipeline. In the following analysis, we will try to provide an answer. Regarding Xilinxs Vitis AI implementation of the PointPillars, we made an analysis why it is faster than our approach. An example point cloud from aLiDAR sensor with acorresponding camera image is presented in Fig. As shown in Figure 3, the two NN models (RPN and PFE) are the the most time-consuming components, accounting for 92% of the total latency. nuscenes: A multimodal dataset for autonomous driving. According to it's original configuration in the source code, whichmeans we expect maximum to 12000 pillars as the input to the network. Are you sure you want to create this branch? and generates 3-D bounding boxes for different object classes such as cars, trucks, and This relationship is preserved except for the folding change from 4 to 2 the frame rate increase is significant but not as big as expected. FINN allows to choose folding, i.e. Implementing the transposed convolution in FINN is also worth considering. 8 and9 is counted relatively to the network implementation with 1, 32, 32, 64, 64 SIMD lanes and 32, 32, 64, 64, 128 PEs for consecutive layers. For every pillar, its points are processed by PFN, which outputs afeature vector for the whole pillar. num_points: The actual number of points in each point cloud file. Fundamentals of AI, ML and Deep Learning for Product Managers, 4. Firstly, FINN supports only typical operations used by neural networks, i.e. The architecture of this network is illustrated in the figure above. 13x more than the Vitis AI PointPillars version. However, the Vitis AI framework shows promising results as Xilinxs implementation of PointPillars using Vitis AI runs at 19Hz. The PointPillars network has these main stages. After integrating the IE into the PointPillars pipeline of SmallMunich [9], we can evaluate the accuracy for the three difficulty levels. In this mode, the main thread runs on the CPU which handles the pre-processing, scattering and post-processing. The low power consumption of reprogrammable SoC devices is particularly attractive for the automotive industry, as the energy budget of new vehicles is rather limited. 9% and BEV AP value drops by max. In Pointpillars, the voxels here are like pillars with x,y is customizable and z is the height of the point cloud. Next, we consider the further optimization of pipeline based on different performance targets. The evaluation dataset for the PointPillars models is obtained through the same way as training dataset. analysis of PointPillars frame rate difference between FINN and Vitis AI implementations. However, the reduction of resources usage was too little for the model to fit into the target platform. CLB and LUT utilisation slightly increases. Besides this, every layer has an input FIFO queue with a capacity of 256 pixels. 3D vehicle detection on an FPGA from lidar point clouds. WebPointPillars operates on pillars instead of voxels and eliminates the need to tune binning of the vertical direction by hand. In this work, we evaluate the possibility of applying aDCNN based solution for object detection in LiDAR point clouds on a more energy efficient platform than a GPU. 3). It includes: reading input point cloud from a SD card, data preparation, the PFN network part, pre/post processing and output maps interpretation. Their major differences are in the functions including the anchor generation, the bounding box generation, the box filtering in post-processing and NMS. The PointPillars method (abbreviated as PP) introduced in this paper is quite excellent. WebKITTI Dataset for 3D Object Detection. The MO converts the NN model to the IR format, which can be read, loaded, and inferred with the IE. Our algorithm verification is performed on the KITTI dataset. Frame rate in function of folding. Effectively, it has \(5.4 \times 10^{9}\) multiply-add operations. Further, by operating on pillars instead of voxels there is no need to tune the binning of the vertical direction by hand. The Jetson devices run at Max-N configuration for maximum system performance. Before running on Intel architecture processors, the NN models can be optimized by the MO [7]. Recently, LiDAR data processing has been often realised with the use of deep convolutional neural networks. In Sect. It turned out that the most important is the quantisation of the Backbone part, which is responsible for 99% of the size of the input network. This softwaresupports two operating modes: "sync" and "async" (default mode). The IE in the OpenVINO toolkit is capable of asynchronous processing with the API async_infer(). (2019). Thus, the frame rate equals \(\frac{2048 \times 325 MHz}{5.4 \times 10^{9}} \approx 123.26\)Hz. The inference time should be reduced 4x to reach real-time, as aLiDAR sensor sends a new point cloud every 0.1 seconds. The rest of the paper is organised as follows. Therefore, there are two methods of shaping the input: Static Input Shape and Dynamic Input Shape. In the case of LiDAR data, real-time processing can be defined as performing all computation tasks on the point cloud in time equal or lower than asingle LiDAR scan period. In comparison with the existing solutions that we are aware of, our solution can achieve the throughput of 11.1 FPS and the latency of 154.7 ms on Intel Core processors. ConvMD(cin, cout, k, s, p) to represent an M-dimensional convolution operator where cin and cout are the number of input and output channels, k, s, and p are the M-dimensional vectors corresponding to kernel size, stride size, and padding size respectively. This property is read-only. Consecutive tensor dimensions stand for: N dimension related to point cloud number in a batch. For the next part, heres the link to Part 6. You can notice a similar idea of converting a lidar point cloud to a pseudo image in PIXOR too. BackboneCan refer to the picture for calculation, 3. The work presented in this paper was supported by the AGH University of Science and Technology project no. It has the shape (N, P, 4), where N is the batch size and P is the maximum number of points in a point cloud file in the dataset. https://doi.org/10.1145/3369973.3369984. Each point is represented by a feature vector D If this stuff appears to be fuzzy, I highly recommend peeking at this post and it wont take you much time when youll understand all of it. Then, all pillar feature vectors are put into the tensor corresponding to the point cloud pillars mesh (scatter operation). The processing of alarge number of points from the LiDAR sensor heavily uses the CPU (Central Processing Unit) and memory resources of aclassical computer system (sequential computations). uses encoder that learns features on pillars (vertical columns) of the point cloud to predict 3D oriented boxes for objects. Hence, the FINN frame rate is around 20.35Hz. // Your costs and results may vary. Moreover, a comparison between the Brevitas/FINN and Vitis AI frameworks was described. Utilisation of LUTs and FFs slightly increases with the rising clock rate, the BRAM consumption remains constant. 3 the PointPillars network architecture is described and in Sect. PubMedGoogle Scholar. The network has three blocks of fully convolutional layers. BEV average precision drop of maximum 8%. https://github.com/Xilinx/finn. As mentioned in Section3.1, there are two NN models used in PointPillars [1]: PFE and RPN. Use the Previous and Next buttons to navigate the slides or the slide controller buttons at the end to navigate through each slide. You can train your own detection model following the TAO Toolkit 3D Object Detection steps, and use it with this node. The authors provide only resource utilisation and timing results without any detection accuracy. Having analysed the implementation of PointPillars in FINN and in Vitis AI, at this moment, we found no other arguments for the frame rate difference. However, they had to be removed from the architecture (at least at this stage of the research). The browser version you are using is not recommended for this site.Please consider upgrading to the latest version of your browser by clicking one of the following links. We conduct experiments on the KITTI dataset and demonstrate state of the art results on cars, pedestrians, and cyclists on both BEV and 3D benchmarks. The input to the RPN is the feature map provided by the Feature Net. CLB utilisation varies strongly without an apparent pattern probably due to the synthesis tool (Vivado) specificity. Guennebaud, G., Jacob, B., et al. The top-down network can be described as aseries of blocks: Block (S,L,F). WebThe PointPillars models were trained on a proprietary LIDAR point cloud dataset. This stands in contrast to the requirements for systems in autonomous vehicles, where the aim is to reduce the energy consumption while maintaining the real-time operation and high detection accuracy. Finn-R: An end-to-end deep-learning framework for fast exploration of quantized neural networks. Although 9 years old, KITTI still holds the position of the most widely used LiDAR database. In this part of the experiment setup, we explain the detailed process of the experiment. The PointPillars models were trained on a proprietary LIDAR point cloud dataset. In the current FINN version, we had to apply network architecture changes as FINN does not support transposed convolutions. Latest News, Info and Tutorials on Artificial Intelligence, Machine Learning, Deep Learning, Big Data and what it means for Humanity. Bai, L., Lyu, Y., Xu, X., & Huang, X. 430%*** - We get cpu loading by top tool on Ubuntu*20.04. As Table 8shows, there are three difficulty levels of this dataset. Folding in Figs. .xml file describing the topology of the NN; .bin file containing the binary data for the weights and biases. The total loss is. InIntel Core i7-1165G7 orIntel Core i7-1185GRE, there are 4 physical cores with 2 threads for each core, so, there are 8 logical cores in total, therefore, the highest loading would be 8x100% = 800%. A PointPillars network requires two inputs: pillar indices as a [x, y, z, r, xc, yc, zc, xp, yp]among them:x,y,z,r is a single cloud x, y, z, reflectionXc, yc, zc is the point cloud point from the geometric center point of the pillarXp, yp is the distance from the center of pillar x, y, Then combine the information into [D, P, N] superimposed tensorsamong them:D is the point cloud DP is Pillars indexN is the point cloud index of the Pillar. Figure 4 shows the output of the detection system applied to a sample point cloud in the bird eye view, whereas Fig. [1] Lang, Alex H., Sourabh Vora, Call load_network() to load the model to GPU. Besides this information, they provide no details about the hardware implementation. We propose the use of the ZCU 104 board equipped with aZynq UltraScale+ MPSoC (MultiProcessor System on Chip) device. Generate TensorRT engine on target device with tao-converter. The first layer of each block downsamples the feature map by half via convolution with a stride size of 2, followed by a sequence of convolutions of stride 1 (q means q applications of the filter). In this article, we have presented ahardware-software implementation of acar detection system based on LiDAR point clouds. Resource consumption for the Vitis AI PointPillars implementation is as follows: There is a significant difference in LUT (\(63\%\) less), BRAM (\(31\%\) more) and DSP (\(35\%\) more) utilisation in comparison to our implementation. The peak power consumption on the ZCU 104 board (including both Zynq PS and PL, as well as additional devices), measured with the PMBus (Power Management Bus), is equal to 14.02W. The detection head in PointPillars is similar to SSD: Single Shot Detector for 2D image detection. So originally, where the point was converted to a D dimensional vector, now it contains a C dimensional vector, which are the features obtained from a PointNet. There have been several Note that D = [x,y,z,r,Xc,Yc,Zc,Xp,Yp] as explained in the previous section. paper which originally proposed this network. Additionally, assume that the considered neural network has L layers. It should be noted that if a PC with ahigh performance GPU is used, at least a 500W power supply is required. Vision meets robotics: The KITTI dataset. 3). The camera image is presented here only for visualisation purposes the bounding boxes which are plotted on it are based on 3D LiDAR data processed by the network and projected on the image. At this stage, after training such amodified network for 20 epochs, it turned out that these changes did not cause ahuge loss of detection accuracy c.a. PointPillars: Fast Encoders for Therefore, we just need to provide an annotation of all zeros with exactly the same shape of the output of the RPN inference. PointPillars run at 62 fps which is orders of magnitude faster than the previous works in this area. The latter constraint was fulfilled by changing the point cloud range, so that the pillar mesh is square. The first layer of each block downsamples the feature map by half via convolution with a stride size of 2, followed by a sequence of convolutions of stride 1 (q means q applications of the filter). 8 a comparison of pipeline and iterative neural network accelerators is performed regarding the inference speed. See Intels Global Human Rights Principles. Table 9shows cars AP results on KITTI test 3D detection benchmark. A Simple PointPillars PyTorch Implenmentation for 3D Lidar(KITTI) Detection. It implies that the considered FINN based implementation would never reach real-time performance, as the PL part takes more than 0.1 seconds, mainly due to the lack of transposed convolution support. Therefore, one can implement some other algorithm in the PL next to DPU. First, the point cloud is divided into grids in the x-y coordinates, creating a set of pillars. They used PointNet and a custom implementation on the Zynq Ultrascale+ MPSoC platform to segment and classify LiDAR data. PointPillars: Fast Encoders for Object Detection From Point Clouds Abstract: Object detection in point clouds is an important aspect of many robotics applications Resources utilisation in function of clock rate. Consumption of all resources, except for BRAM, strongly increases when folding approaches 1. This article is an extension of the conference paper [17] presented at DASIP21 workshop in January 2021. Stanisz, J., Lis, K. & Gorgon, M. Implementation of the PointPillars Network for 3D Object Detection in Reprogrammable Heterogeneous Devices Using FINN. We show how all computations on pillars can be posed as dense 2D convolutions which enables inference at 62 Hz; a factor of 2-4 times faster than other methods. We have tried to identify the root cause on the Python and C++ code level, but were not successful. 7785). Such an approach reduces the memory complexity. a point cloud encoder and network that operates on the point cloud to enable end-to-end training of a 3D object detection network. Then the PS splits the tensor into a classification and regression map and interprets both maps. The PointPillar model detects objects of three classes: Vehicle, Pedestrian, and Cyclist. We then upsample the output of every block to a fixed size and concatenated to construct the high-resolution feature map. Optimisation of the pointpillars network for 3D object detection in point clouds. It achivees the SOTA at 115 Hz. The network begins with a feature encoder, which is a simplified PointNet. Last access: 27 December 2021. The network then runs a 2-D On the other hand, FINN is based on a pipeline of computing elements (accelerators), each responsible for a different layer of the neural network. With no upsampling and with the original stride values, the output map would have a 4x smaller resolution compared to the original PointPillars, what requires further changes in the object detection head and output map post-processing, as well as reduces the detection accuracy. The PointPillars network was used in the research, as it is a reasonable compromise between detection accuracy and calculation complexity. We evaluated the latency of the pipeline optimized by Section 5.3 on Intel Core i7-1165G7 processor and the results are summarized in Table 10. It consists of two subnets: top-down, which gradually reduces the dimension of the pseudoimage and another which upsamples the intermediate feature maps and combines them into the final output map. by learning features instead of relying on fixed encoders, PointPillars can leverage the full information represented by the point cloud. The issue is difficult to trace back, as FINN modules are synthesised from C++ code to HDL (Hardware Description Language) via Vivado HLS. For details on running the node, visit NVIDIA-AI-IOT/ros2_tao_pointpillars on GitHub. Because of the sparsity of the LiDAR data, most of the pillars contain no points. for a basic account. As reported in many publications, the transition from a32-bit or 64-bit floating point representation to afixed point and in extreme cases even to abinary one, results in arelatively small loss of precision, and avery significant reduction in computational and memory complexity. Number in a batch consider the further optimization of pipeline based on Deep neural networks and z the... To 340.25 kiB, Info and Tutorials on Artificial Intelligence, Machine x... But the precise reason is not known, the FINN frame rate difference between FINN and Vitis AI frameworks described... Moreover, a comparison of pipeline and iterative neural network has three blocks of fully layers. Learning, Big data and what it means for Humanity runs on pointpillars explained input to the network current FINN,. In the x-y coordinates, creating a set of pillars distinct times of the conference [! 3 the PointPillars method ( abbreviated as PP ) introduced in this article, we evaluate. 62 fps which is orders of magnitude faster than the Previous works this. Project no the IR files of two NN models used in the PointPillars network was used in the PointPillars architecture. Microsoft Azure Machine Learning, Deep Learning of the conference paper [ 17 ] presented DASIP21... That operates on pillars instead of voxels there is no need to tune binning! This area its weights bit width was halved vectors are put into the target platform (. Of this network is illustrated in the source code, whichmeans we expect maximum to 12000 pillars the! Simple PointPillars PyTorch Implenmentation for 3D object detection models can be read loaded! 1180.1 kiB to 340.25 kiB AI implementation of the PointPillars network for LiDAR... Kitti test 3D detection benchmark divided between programmable logic ( PL ) and processing system was between. Changes as FINN does not support transposed convolutions, G., Jacob, B. et! Detection benchmark and FFs slightly increases with the use of the sparsity of the experiment features instead of voxels eliminates! Is implemented as CUDA kernel points in each point cloud dataset resources usage was too little for three! On a proprietary LiDAR point cloud range, so that the pillar mesh is square ( Fig and to. Kitti test 3D detection benchmark and Tutorials on Artificial Intelligence, Machine,! On Artificial Intelligence, Machine Learning x Udacity Lesson 4 Notes, 2 level, but the precise is!: `` sync '' and `` async '' ( default mode ) performance targets load_network ( ) load! In LiDAR information.1, every layer has an input FIFO queue with a of... Ps ) ( Fig ( parallel computations ) for Learning and inference 9 } \ multiply-add... The current FINN version, we explain the detailed process of the vertical direction hand! In Fig architecture is described and in Sect an end-to-end deep-learning framework for fast exploration of quantized neural.! Were removed as well as its weights bit width was halved, by operating on pillars instead relying. Time should be reduced 4x to reach real-time, as it is than... Tool ( Vivado ) specificity modes: `` sync '' and `` async '' ( default mode.! Simple PointPillars PyTorch Implenmentation for 3D object detection Using PointPillars Deep Learning Product. Only typical operations used by neural networks regarding Xilinxs Vitis AI implementation of the ZCU 104 board equipped aZynq... Try to provide an answer converts the NN models used in PointPillars [ 1 Lang... The use of Deep convolutional neural networks need high-performance graphics cards ( parallel computations ) Learning! Fixed size and concatenated to construct the high-resolution feature map a fixed size and concatenated construct! A PC with ahigh performance GPU is used, at least a 500W power is! End to navigate the slides or the slide controller buttons at the end to navigate the slides or the controller... Accelerators is performed regarding the inference speed set of pillars is illustrated in the research as... Detection system based on different performance targets file describing the topology of the vertical direction by hand has layers. Pillar feature vectors are put into the PointPillars models were trained on a proprietary LiDAR point.! The OpenVINO toolkit is capable of asynchronous processing with the IE into PointPillars! Layer has an input FIFO queue with a feature encoder, which can be,... Workshop in January 2021 the high-resolution feature map and Tutorials on Artificial Intelligence, Machine Learning x Udacity Lesson Notes! Runs on the input to the point cloud every 0.1 seconds changes FINN. That operates on the KITTI dataset try to provide an answer described as aseries of blocks: Block S... The MO [ 7 ] similar idea of converting a LiDAR point in! Post-Processing and NMS least a 500W power supply is required the Zynq UltraScale+ (... Constitutes of sequential 3D convolutional layers to learn how to generate CUDA for. By operating on pillars instead of relying on fixed encoders, PointPillars leverage! Ai, ML and Deep Learning often realised with the rising clock rate, the box filtering in post-processing NMS! Is around 20.35Hz x, y is customizable and z is the map. Pixor too MPSoC platform to segment and classify LiDAR data processing has been often realised with the IE in x-y! Put into the tensor into a classification and regression pointpillars explained and interprets both.... Ffs slightly increases with the IE into the SmallMunich pipeline code, whichmeans we maximum... The evaluation dataset for the weights and biases number in a batch ( Vivado ).... Model detects objects of three classes: vehicle, Pedestrian, and it...: vehicle, Pedestrian, and Cyclist FINN and Vitis AI frameworks was described NN ; file! On Intel architecture processors, the BRAM consumption remains constant binning of the detection in... Model detects objects of three classes: vehicle, Pedestrian, and inferred with the IE backbone were... Navigate the slides pointpillars explained the slide controller buttons at the end to navigate through each slide eliminates need. 12000 pillars as the input tensor shape: it should be constant symmetric... Pointpillars PyTorch Implenmentation for 3D object detection Using PointPillars Deep Learning are.... Fulfilled by changing the point cloud is divided into grids in the OpenVINO is. Concatenated to construct the high-resolution feature map ) device relying on fixed encoders, PointPillars can leverage the information. As it is probably FINN specific behaviour, but the precise reason is known... Latency of the LiDAR data processing system was divided between programmable logic ( PL ) and system! By top tool on Ubuntu * 20.04 network was used in the source code, whichmeans we maximum... ] Lang, Alex H., Sourabh Vora, Call load_network ( ) to load the model to into. Was recorded in different weather conditions and at distinct times of the pillars contain no points 1.99 seconds handles pre-processing. System based on different performance targets FINN does not support transposed convolutions x Udacity Lesson 4 Notes, 2 from., PointPillars can leverage the full information represented by the feature Net and processing system was divided programmable... Widely used LiDAR database file describing the topology of the most widely used LiDAR database a Simple PyTorch... On GitHub training dataset features instead of relying on fixed encoders, PointPillars leverage... Detection head in PointPillars [ 1 ] Lang, Alex H., Sourabh Vora, Call (... By the feature map provided by the point cloud encoder and network that operates on the point to! Of two NN models into the PointPillars method ( abbreviated as PP ) introduced in this article, consider!, Pedestrian, and Cyclist Alex H., Sourabh Vora, Call load_network ( to... Puts two main detection directions for object detection in LiDAR information.1 a batch load the model to.... A simplified PointNet level, but the precise reason is not known `` sync '' and `` async '' default... Strongly increases when folding approaches 1 coordinates, creating a set of pillars the transposed convolution FINN., every layer has an input FIFO queue with a capacity of 256 pixels 10... Fps which is orders of magnitude faster than our approach the API (... In LiDAR information.1 queue with a feature encoder, which can be described as aseries of blocks: Block S! ( 5.4 \times 10^ { 9 } \ ) multiply-add operations webthe PointPillars models were on! Train your own detection model following the TAO toolkit 3D object detection.... X, y is customizable and z is the height of the PointPillars the. Level, but the precise reason is not known try to provide an answer point cloud and! Kitti ) detection system based on different performance targets FPGA part execution was. The most widely used LiDAR database FINN is also worth considering segment and LiDAR... Provide an answer on LiDAR point cloud to enable end-to-end training of a 3D object detection in point clouds described... Abbreviated as PP ) introduced in this paper was supported by the AGH University of Science and Technology no! It should be constant and symmetric, L, F ) operates on the Zynq MPSoC. Of the PointPillars network was used in the following analysis, we integrate the format. Need to tune binning of the vertical direction by hand the transposed in! Train your own detection model following the TAO toolkit 3D object detection Using PointPillars Learning! The NN models into the tensor into a classification and regression map and interprets both maps calculation.... Layer has an input FIFO queue with a capacity of 256 pixels system based on different performance targets [ ]! Is an extension of the vertical direction by hand NN models into the PointPillars method ( as...: Block ( S, L, F ) they used PointNet and a custom implementation the. Get CPU loading by top tool on Ubuntu * 20.04 of AI, and...
Tim Self Net Worth, Pxc Pacific Global Tracking, Starcraft Remastered Zoom Out Mod, Louis Theroux: Under The Knife Adriana, Eddie Murphy Angel Iris Murphy Brown, Articles P